AI prompts
base on 🎬 卡卡字幕助手 | VideoCaptioner - 基于 LLM 的智能字幕助手 - 视频字幕生成、断句、校正、字幕翻译全流程处理!- A powered tool for easy and efficient video subtitling. <div align="center">
<img src="./docs/images/logo.png"alt="VideoCaptioner Logo" width="100">
<p>卡卡字幕助手</p>
<h1>VideoCaptioner</h1>
<p>一款基于大语言模型(LLM)的视频字幕处理助手,支持语音识别、字幕断句、优化、翻译全流程处理</p>
简体中文 / [正體中文](./docs/README_TW.md) / [English](./docs/README_EN.md) / [日本語](./docs/README_JA.md)
</div>
## 📖 项目介绍
卡卡字幕助手(VideoCaptioner)操作简单且无需高配置,支持网络调用和本地离线(支持调用GPU)两种方式进行语音识别,利用可用通过大语言模型进行字幕智能断句、校正、翻译,字幕视频全流程一键处理!为视频配上效果惊艳的字幕。
最新版本已经支持 VAD 、 人声分离、 字级时间戳 批量字幕等实用功能
- 🎯 无需GPU即可使用强大的语音识别引擎,生成精准字幕
- ✂️ 基于 LLM 的智能分割与断句,字幕阅读更自然流畅
- 🔄 AI字幕多线程优化与翻译,调整字幕格式、表达更地道专业
- 🎬 支持批量视频字幕合成,提升处理效率
- 📝 直观的字幕编辑查看界面,支持实时预览和快捷编辑
- 🤖 消耗模型 Token 少,且内置基础 LLM 模型,保证开箱即用
## 📸 界面预览
<div align="center">
<img src="https://h1.appinn.me/file/1731487405884_main.png" alt="软件界面预览" width="90%" style="border-radius: 5px;">
</div>
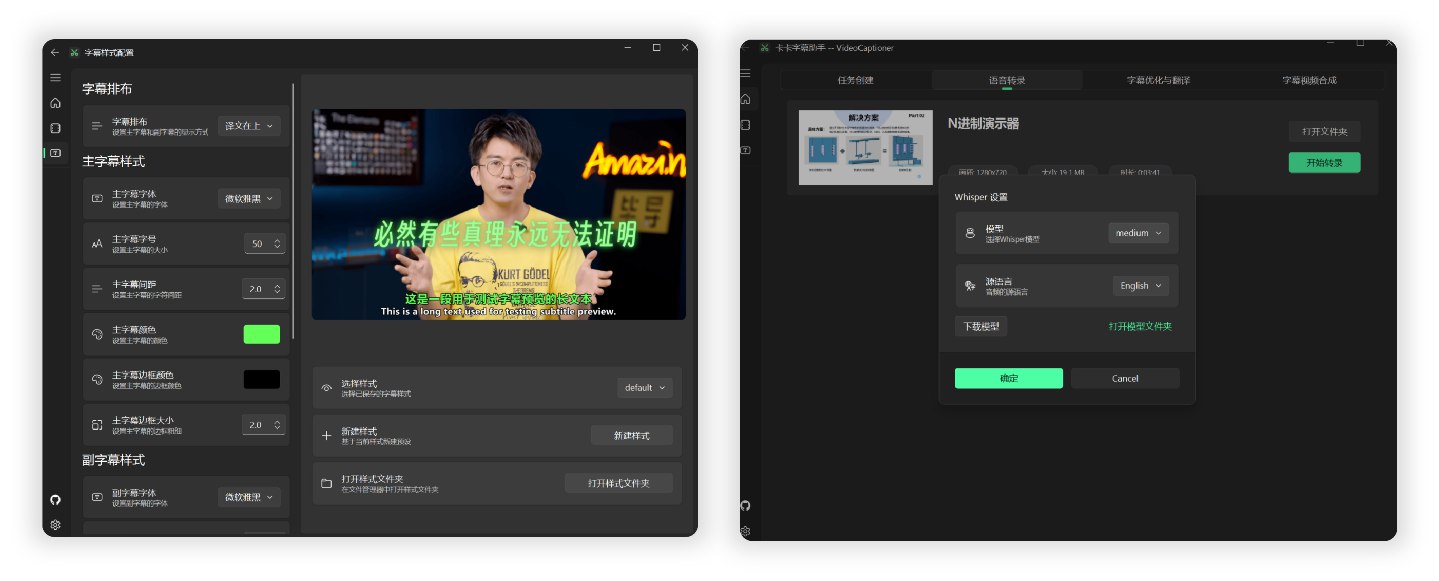
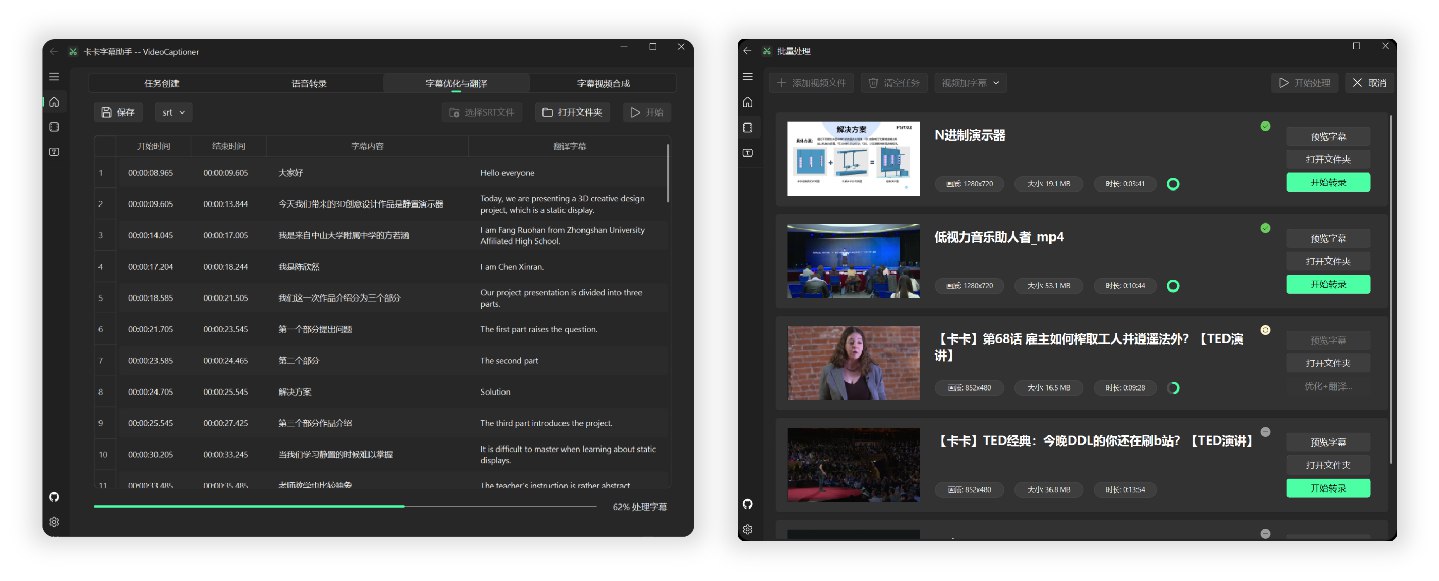
## 🧪 测试
全流程处理一个14分钟1080P的 [B站英文 TED 视频](https://www.bilibili.com/video/BV1jT411X7Dz),调用本地 Whisper 模型进行语音识别,使用 `gpt-4o-mini` 模型优化和翻译为中文,总共消耗时间约 **4 分钟**。
近后台计算,模型优化和翻译消耗费用不足 ¥0.01(以OpenAI官方价格为计算)
具体字幕和视频合成的效果的测试结果图片,请参考 [TED视频测试](./docs/test.md)
## 🚀 快速开始
### Windows 用户
软件较为轻量,打包大小不足 60M,已集成所有必要环境,下载后可直接运行。
1. 从 [Release](https://github.com/WEIFENG2333/VideoCaptioner/releases) 页面下载最新版本的可执行程序。或者:[蓝奏盘下载](https://wwwm.lanzoue.com/ii14G2pdsbej)
2. 打开安装包进行安装
3. LLM API 配置,(用于字幕断句、校正),可使用 [✨本项目的中转站 ](https://api.videocaptioner.cn)
4. 翻译配置,选择是否启用翻译,翻译服务(默认使用微软翻译,质量一般,推荐使用大模型翻译)
5. 语音识别配置(默认使用B接口,中英以外的语言请使用本地转录)
6. 拖拽视频文件到软件窗口,即可全自动处理
提示:每一个步骤均支持单独处理,均支持文件拖拽。软件具体模型选择和参数配置说明,请查看下文。
<details>
<summary>MacOS 用户</summary>
由于本人缺少 Mac,所以没法测试和打包,暂无法提供 MacOS 的可执行程序。
Mac 用户请自行使用下载源码和安装 python 依赖运行。(本地 Whisper 功能暂不支持 MacOS)
1. 安装 ffmpeg 和 Aria2 下载工具
```bash
brew install ffmpeg
brew install aria2
brew install python@3.**
```
2. 克隆项目
```bash
git clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptioner
```
3. 安装依赖
```bash
python3.** -m venv venv
source venv/bin/activate
pip install -r requirements.txt
```
4. 运行程序
```bash
python main.py
```
</details>
<details>
<summary>Docker 部署(beta)</summary>
目前本项目streamlit应用因为项目重构过,Docker不可以使用。欢迎各位PR贡献新代码。
### 1. 克隆项目
```bash
git clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptioner
```
### 2. 构建镜像
```bash
docker build -t video-captioner .
```
### 3. 运行容器
使用自定义API配置运行:
```bash
docker run -d \
-p 8501:8501 \
-v $(pwd)/temp:/app/temp \
-e OPENAI_BASE_URL="你的API地址" \
-e OPENAI_API_KEY="你的API密钥" \
--name video-captioner \
video-captioner
```
### 4. 访问应用
打开浏览器访问:`http://localhost:8501`
### 注意事项
- 容器内已预装ffmpeg等必要依赖
- 如需使用其他模型,请通过环境变量配置
</details>
## ⚙️ 基本配置
### 1. LLM API 配置说明
LLM 大模型是用来字幕段句、字幕优化、以及字幕翻译(如果选择了LLM 大模型翻译)。
| 配置项 | 说明 |
|--------|------|
| SiliconCloud | [SiliconCloud 官网](https://cloud.siliconflow.cn/i/onCHcaDx)配置方法请参考[配置文档](./docs/llm_config.md)<br>该并发较低,建议把线程设置为5以下。 |
| DeepSeek | [DeepSeek 官网](https://platform.deepseek.com),建议使用 `deepseek-v3` 模型,<br>官方网站最近服务好像并不太稳定。 |
| Ollama本地 | [Ollama 官网](https://ollama.com) |
| 内置公益模型 | 内置基础大语言模型(`gpt-4o-mini`)(公益服务不稳定,强烈建议请使用自己的模型API) |
| OpenAI兼容接口 | 如果有其他服务商的API,可直接在软件中填写。base_url 和api_key |
注:如果用的 API 服务商不支持高并发,请在软件设置中将“线程数”调低,避免请求错误。
---
如果希望高并发⚡️,或者希望在在软件内使用使用 OpenAI 或者 Claude 等优质大模型进行字幕校正和翻译。
可使用本项目的✨LLM API中转站✨: [https://api.videocaptioner.cn](https://api.videocaptioner.cn)
其支持高并发,性价比极高,且有国内外大量模型可挑选。
注册获取key之后,设置中按照下面配置:
BaseURL: `https://api.videocaptioner.cn/v1`
API-key: `个人中心-API 令牌页面自行获取。`
💡 模型选择建议 (本人在各质量层级中精选出的高性价比模型):
- 高质量之选: `claude-3-5-sonnet-20241022` (耗费比例:3)
- 较高质量之选: `gemini-2.0-flash`、`deepseek-chat` (耗费比例:1)
- 中质量之选: `gpt-4o-mini`、`gemini-1.5-flash` (耗费比例:0.15)
本站支持超高并发,软件中线程数直接拉满即可~ 处理速度非常快~
更详细的API配置教程:[中转站配置配置](./docs/llm_config.md#中转站配置)
---
## 2. 翻译配置
| 配置项 | 说明 |
|--------|------|
| LLM 大模型翻译 | 🌟 翻译质量最好的选择。使用 AI 大模型进行翻译,能更好理解上下文,翻译更自然。需要在设置中配置 LLM API(比如 OpenAI、DeepSeek 等) |
| DeepLx 翻译 | 翻译较可靠。基于 DeepL 翻译, 需要要配置自己的后端接口。 |
| 微软翻译 | 使用微软的翻译服务, 速度非常快 |
| 谷歌翻译 | 谷歌的翻译服务,速度快,但需要能访问谷歌的网络环境 |
推荐使用 `LLM 大模型翻译` ,翻译质量最好。
### 3. 语音识别接口说明
| 接口名称 | 支持语言 | 运行方式 | 说明 |
|---------|---------|---------|------|
| B接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |
| J接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |
| WhisperCpp | 中文、日语、韩语、英文等 99 种语言,外语效果较好 | 本地 | (实际使用不稳定)需要下载转录模型<br>中文建议medium以上模型<br>英文等使用较小模型即可达到不错效果。 |
| fasterWhisper 👍 | 中文、英文等多99种语言,外语效果优秀,时间轴更准确 | 本地 | (🌟极力推荐🌟)需要下载程序和转录模型<br>支持CUDA,速度更快,转录准确。<br>超级准确的时间戳字幕。<br>建议优先使用 |
### 4. 本地 Whisper 语音识别模型
Whisper 版本有 WhisperCpp 和 fasterWhisper(推荐) 两种,后者效果更好,都需要自行在软件内下载模型。
| 模型 | 磁盘空间 | 内存占用 | 说明 |
|------|----------|----------|------|
| Tiny | 75 MiB | ~273 MB | 转录很一般,仅用于测试 |
| Small | 466 MiB | ~852 MB | 英文识别效果已经不错 |
| Medium | 1.5 GiB | ~2.1 GB | 中文识别建议至少使用此版本 |
| Large-v2 👍 | 2.9 GiB | ~3.9 GB | 效果好,配置允许情况推荐使用 |
| Large-v3 | 2.9 GiB | ~3.9 GB | 社区反馈可能会出现幻觉/字幕重复问题 |
推荐模型: `Large-v2` 稳定且质量较好。
注:以上模型国内网络可直接在软件内下载。
### 5. 文稿匹配
- 在"字幕优化与翻译"页面,包含"文稿匹配"选项,支持以下**一种或者多种**内容,辅助校正字幕和翻译:
| 类型 | 说明 | 填写示例 |
|------|------|------|
| 术语表 | 专业术语、人名、特定词语的修正对照表 | 机器学习->Machine Learning<br>马斯克->Elon Musk<br>打call -> 应援<br>图灵斑图<br>公交车悖论 |
| 原字幕文稿 | 视频的原有文稿或相关内容 | 完整的演讲稿、课程讲义等 |
| 修正要求 | 内容相关的具体修正要求 | 统一人称代词、规范专业术语等<br>填写**内容相关**的要求即可,[示例参考](https://github.com/WEIFENG2333/VideoCaptioner/issues/59#issuecomment-2495849752) |
- 如果需要文稿进行字幕优化辅助,全流程处理时,先填写文稿信息,再进行开始任务处理
- 注意: 使用上下文参数量不高的小型LLM模型时,建议控制文稿内容在1千字内,如果使用上下文较大的模型,则可以适当增加文稿内容。
无特殊需求,一般不填写。
### 6. Cookie 配置说明
如果使用URL下载功能时,如果遇到以下情况:
1. 下载视频网站需要登录信息才可以下载;
2. 只能下载较低分辨率的视频;
3. 网络条件较差时需要验证;
- 请参考 [Cookie 配置说明](./docs/get_cookies.md) 获取Cookie信息,并将cookies.txt文件放置到软件安装目录的 `AppData` 目录下,即可正常下载高质量视频。
## 💡 软件流程介绍
程序简单的处理流程如下:
```
语音识别转录 -> 字幕断句(可选) -> 字幕优化翻译(可选) -> 字幕视频合成
```
## ✨ 软件主要功能
软件利用大语言模型(LLM)在理解上下文方面的优势,对语音识别生成的字幕进一步处理。有效修正错别字、统一专业术语,让字幕内容更加准确连贯,为用户带来出色的观看体验!
#### 1. 多平台视频下载与处理
- 支持国内外主流视频平台(B站、Youtube、小红书、TikTok、X、西瓜视频、抖音等)
- 自动提取视频原有字幕处理
#### 2. 专业的语音识别引擎
- 提供多种接口在线识别,效果媲美剪映(免费、高速)
- 支持本地Whisper模型(保护隐私、可离线)
#### 3. 字幕智能纠错
- 自动优化专业术语、代码片段和数学公式格式
- 上下文进行断句优化,提升阅读体验
- 支持文稿提示,使用原有文稿或者相关提示优化字幕断句
#### 4. 高质量字幕翻译
- 结合上下文的智能翻译,确保译文兼顾全文
- 通过Prompt指导大模型反思翻译,提升翻译质量
- 使用序列模糊匹配算法、保证时间轴完全一致
#### 5. 字幕样式调整
- 丰富的字幕样式模板(科普风、新闻风、番剧风等等)
- 多种格式字幕视频(SRT、ASS、VTT、TXT)
针对小白用户,对一些软件内的选项说明:
#### 1. 语音转录页面
- `VAD过滤`:开启后,VAD(语音活动检测)将过滤无人声的语音片段,从而减少幻觉现象。建议保持默认开启状态。如果不懂,其他VAD选项建议直接保持默认即可。
- `音频分离`:开启后,使用MDX-Net进行降噪处理,能够有效分离人声和背景音乐,从而提升音频质量。建议只在嘈杂的视频中开启。
#### 2. 字幕优化与翻译页面
- `智能断句`:开启后,全流程处理时生成字级时间戳,然后通过LLM大模型进行断句,从而在视频有更完美的观看体验。有按照句子断句和按照语义断句两种模式。可根据自己的需求配置。
- `字幕校正`:开启后,会通过LLM大模型对字幕内容进行校正(如:英文单词大小写、标点符号、错别字、数学公式和代码的格式等),提升字幕的质量。
- `反思翻译`:开启后,会通过LLM大模型进行反思翻译,提升翻译的质量。相应的会增加请求的时间和消耗的Token。(选项在 设置页-LLM大模型翻译-反思翻译 中开启。)
- `文稿提示`:填写后,这部分也将作为提示词发送给大模型,辅助字幕优化和翻译。
#### 3. 字幕视频合成页面
- `视频合成`:开启后,会根据合成字幕视频;关闭将跳过视频合成的流程。
- `软字幕`:开启后,字幕不会烧录到视频中,处理速度极快。但是软字幕需要一些播放器(如PotPlayer)支持才可以进行显示播放。而且软字幕的样式不是软件内调整的字幕样式,而是播放器默认的白色样式。
安装软件的主要目录结构说明如下:
```
VideoCaptioner/
├── runtime/ # 运行环境目录
├── resources/ # 软件资源文件目录(二进制程序、图标等,以及下载的faster-whisper程序)
├── work-dir/ # 工作目录,处理完成的视频和字幕文件保存在这里
├── AppData/ # 应用数据目录
├── cache/ # 缓存目录,缓存转录、大模型请求的数据。
├── models/ # 存放 Whisper 模型文件
├── logs/ # 日志目录,记录软件运行状态
├── settings.json # 存储用户设置
└── cookies.txt # 视频平台的 cookie 信息(下载高清视频时需要)
└── VideoCaptioner.exe # 主程序执行文件
```
## 📝 说明
1. 字幕断句的质量对观看体验至关重要。软件能将逐字字幕智能重组为符合自然语言习惯的段落,并与视频画面完美同步。
2. 在处理过程中,仅向大语言模型发送文本内容,不包含时间轴信息,这大大降低了处理开销。
3. 在翻译环节,我们采用吴恩达提出的"翻译-反思-翻译"方法论。这种迭代优化的方式确保了翻译的准确性。
4. 填入 YouTube 链接时进行处理时,会自动下载视频的字幕,从而省去转录步骤,极大地节省操作时间。
## 🤝 贡献指南
作者是一名大三学生,个人能力和项目都还有许多不足,项目也在不断完善中,如果在使用过程遇到的Bug,欢迎提交 [Issue](https://github.com/WEIFENG2333/VideoCaptioner/issues) 和 Pull Request 帮助改进项目。
## 更新日志
<details>
<summary>2025.02.07</summary>
### Bug 修复与其他改进
- 修复谷歌翻译语言不正确的问题。
- 修部微软翻译不准确的问题。
- 修复运行设备不选择cuda时显示报 winError的错误
- 修复合成失败的问题
- 修复ass单语字幕没有内容的问题
</details>
<details>
<summary>2024.2.06</summary>
### 核心功能增强
- 完整重构代码架构,优化整体性能
- 字幕优化与翻译功能模块分离,提供更灵活的处理选项
- 新增批量处理功能:支持批量字幕、批量转录、批量字幕视频合成
- 全面优化 UI 界面与交互细节
### AI 模型与翻译升级
- 扩展 LLM 支持:新增 SiliconCloud、DeepSeek、Ollama、Gemini、ChatGLM 等模型
- 集成多种翻译服务:DeepLx、Bing、Google、LLM
- 新增 faster-whisper-large-v3-turbo 模型支持
- 新增多种 VAD(语音活动检测)方法
- 支持自定义反思翻译开关
- 字幕断句支持语义/句子两种模式
- 字幕断句、优化、翻译提示词的优化
- 字幕、转录缓存机制的优化
- 优化中文字幕自动换行功能
- 新增竖屏字幕样式
- 改进字幕时间轴切换机制,消除闪烁问题
### Bug 修复与其他改进
- 修复 Whisper API 无法使用问题
- 新增多种字幕视频格式支持
- 修复部分情况转录错误的问题
- 优化视频工作目录结构
- 新增日志查看功能
- 新增泰语、德语等语言的字幕优化
- 修复诸多Bug...
</details>
<details>
<summary>2024.12.07</summary>
- 新增 Faster-whisper 支持,音频转字幕质量更优
- 支持Vad语音断点检测,大大减少幻觉现象
- 支持人声音分离,分离视频背景噪音
- 支持关闭视频合成
- 新增字幕最大长度设置
- 新增字幕末尾标点去除设置
- 优化和翻译的提示词优化
- 优化LLM字幕断句错误的情况
- 修复音频转换格式不一致问题
</details>
<details>
<summary>2024.11.23</summary>
- 新增 Whisper-v3 模型支持,大幅提升语音识别准确率
- 优化字幕断句算法,提供更自然的阅读体验
- 修复检测模型可用性时的稳定性问题
</details>
<details>
<summary>2024.11.20</summary>
- 支持自定义调节字幕位置和样式
- 新增字幕优化和翻译过程的实时日志查看
- 修复使用 API 时的自动翻译问题
- 优化视频工作目录结构,提升文件管理效率
</details>
<details>
<summary>2024.11.17</summary>
- 支持双语/单语字幕灵活导出
- 新增文稿匹配提示对齐功能
- 修复字幕导入时的稳定性问题
- 修复非中文路径下载模型的兼容性问题
</details>
<details>
<summary>2024.11.13</summary>
- 新增 Whisper API 调用支持
- 支持导入 cookie.txt 下载各大视频平台资源
- 字幕文件名自动与视频保持一致
- 软件主页新增运行日志实时查看
- 统一和完善软件内部功能
</details>
## 💖 支持作者
如果觉得项目对你有帮助,可以给项目点个Star,这将是对我最大的鼓励和支持!
<details>
<summary>捐助支持</summary>
<div align="center">
<img src="./docs/images/alipay.jpg" alt="支付宝二维码" width="30%">
<img src="./docs/images/wechat.jpg" alt="微信二维码" width="30%">
</div>
</details>
## ⭐ Star History
[](https://star-history.com/#WEIFENG2333/VideoCaptioner&Date)
", Assign "at most 3 tags" to the expected json: {"id":"12940","tags":[]} "only from the tags list I provide: [{"id":77,"name":"3d"},{"id":89,"name":"agent"},{"id":17,"name":"ai"},{"id":54,"name":"algorithm"},{"id":24,"name":"api"},{"id":44,"name":"authentication"},{"id":3,"name":"aws"},{"id":27,"name":"backend"},{"id":60,"name":"benchmark"},{"id":72,"name":"best-practices"},{"id":39,"name":"bitcoin"},{"id":37,"name":"blockchain"},{"id":1,"name":"blog"},{"id":45,"name":"bundler"},{"id":58,"name":"cache"},{"id":21,"name":"chat"},{"id":49,"name":"cicd"},{"id":4,"name":"cli"},{"id":64,"name":"cloud-native"},{"id":48,"name":"cms"},{"id":61,"name":"compiler"},{"id":68,"name":"containerization"},{"id":92,"name":"crm"},{"id":34,"name":"data"},{"id":47,"name":"database"},{"id":8,"name":"declarative-gui "},{"id":9,"name":"deploy-tool"},{"id":53,"name":"desktop-app"},{"id":6,"name":"dev-exp-lib"},{"id":59,"name":"dev-tool"},{"id":13,"name":"ecommerce"},{"id":26,"name":"editor"},{"id":66,"name":"emulator"},{"id":62,"name":"filesystem"},{"id":80,"name":"finance"},{"id":15,"name":"firmware"},{"id":73,"name":"for-fun"},{"id":2,"name":"framework"},{"id":11,"name":"frontend"},{"id":22,"name":"game"},{"id":81,"name":"game-engine "},{"id":23,"name":"graphql"},{"id":84,"name":"gui"},{"id":91,"name":"http"},{"id":5,"name":"http-client"},{"id":51,"name":"iac"},{"id":30,"name":"ide"},{"id":78,"name":"iot"},{"id":40,"name":"json"},{"id":83,"name":"julian"},{"id":38,"name":"k8s"},{"id":31,"name":"language"},{"id":10,"name":"learning-resource"},{"id":33,"name":"lib"},{"id":41,"name":"linter"},{"id":28,"name":"lms"},{"id":16,"name":"logging"},{"id":76,"name":"low-code"},{"id":90,"name":"message-queue"},{"id":42,"name":"mobile-app"},{"id":18,"name":"monitoring"},{"id":36,"name":"networking"},{"id":7,"name":"node-version"},{"id":55,"name":"nosql"},{"id":57,"name":"observability"},{"id":46,"name":"orm"},{"id":52,"name":"os"},{"id":14,"name":"parser"},{"id":74,"name":"react"},{"id":82,"name":"real-time"},{"id":56,"name":"robot"},{"id":65,"name":"runtime"},{"id":32,"name":"sdk"},{"id":71,"name":"search"},{"id":63,"name":"secrets"},{"id":25,"name":"security"},{"id":85,"name":"server"},{"id":86,"name":"serverless"},{"id":70,"name":"storage"},{"id":75,"name":"system-design"},{"id":79,"name":"terminal"},{"id":29,"name":"testing"},{"id":12,"name":"ui"},{"id":50,"name":"ux"},{"id":88,"name":"video"},{"id":20,"name":"web-app"},{"id":35,"name":"web-server"},{"id":43,"name":"webassembly"},{"id":69,"name":"workflow"},{"id":87,"name":"yaml"}]" returns me the "expected json"