AI prompts
base on High-speed Large Language Model Serving for Local Deployment # PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
## TL;DR
PowerInfer is a CPU/GPU LLM inference engine leveraging **activation locality** for your device.
<a href="https://trendshift.io/repositories/6186" target="_blank"><img src="https://trendshift.io/api/badge/repositories/6186" alt="SJTU-IPADS%2FPowerInfer | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
[](https://opensource.org/licenses/MIT)
[Project Kanban](https://github.com/orgs/SJTU-IPADS/projects/2/views/2)
## Latest News 🔥
- [2024/6/11] We are thrilled to introduce [PowerInfer-2](https://arxiv.org/abs/2406.06282), our highly optimized inference framework designed specifically for smartphones. With TurboSparse-Mixtral-47B, it achieves an impressive speed of 11.68 tokens per second, which is up to 22 times faster than other state-of-the-art frameworks.
- [2024/6/11] We are thrilled to present [Turbo Sparse](https://arxiv.org/abs/2406.05955), our TurboSparse models for fast inference. With just $0.1M, we sparsified the original Mistral and Mixtral model to nearly 90% sparsity while maintaining superior performance! For a Mixtral-level model, our TurboSparse-Mixtral activates only **4B** parameters!
- [2024/5/20] **Competition Recruitment: CCF-TCArch Customized Computing Challenge 2024**. The CCF TCARCH CCC is a national competition organized by the Technical Committee on Computer Architecture (TCARCH) of the China Computer Federation (CCF). This year's competition aims to optimize the PowerInfer inference engine using the open-source ROCm/HIP. More information about the competition can be found [here](https://ccf-tcarch-ccc.github.io/2024/).
- [2024/5/17] We now provide support for AMD devices with ROCm.
- [2024/3/28] We are trilled to present [Bamboo LLM](https://github.com/SJTU-IPADS/Bamboo) that achieves both top-level performance and unparalleled speed with PowerInfer! Experience it with Bamboo-7B [Base](https://huggingface.co/PowerInfer/Bamboo-base-v0.1-gguf) / [DPO](https://huggingface.co/PowerInfer/Bamboo-DPO-v0.1-gguf).
- [2024/3/14] We supported ProSparse Llama 2 ([7B](https://huggingface.co/SparseLLM/prosparse-llama-2-7b)/[13B](https://huggingface.co/SparseLLM/prosparse-llama-2-13b)), ReLU models with ~90% sparsity, matching original Llama 2's performance (Thanks THUNLP & ModelBest)!
- [2024/1/11] We supported Windows with GPU inference!
- [2023/12/24] We released an online [gradio demo](https://powerinfer-gradio.vercel.app/) for Falcon(ReLU)-40B-FP16!
- [2023/12/19] We officially released PowerInfer!
## Demo 🔥
https://github.com/SJTU-IPADS/PowerInfer/assets/34213478/fe441a42-5fce-448b-a3e5-ea4abb43ba23
PowerInfer v.s. llama.cpp on a single RTX 4090(24G) running Falcon(ReLU)-40B-FP16 with a 11x speedup!
<sub>Both PowerInfer and llama.cpp were running on the same hardware and fully utilized VRAM on RTX 4090.</sub>
> [!NOTE]
> **Live Demo Online⚡️**
>
> Try out our [Gradio server](https://powerinfer-gradio.vercel.app/) hosting Falcon(ReLU)-40B-FP16 on a RTX 4090!
>
> <sub>Experimental and without warranties 🚧</sub>
## Abstract
We introduce PowerInfer, a high-speed Large Language Model (LLM) inference engine on a personal computer (PC)
equipped with a single consumer-grade GPU. The key underlying the design of PowerInfer is exploiting the high **locality**
inherent in LLM inference, characterized by a power-law distribution in neuron activation.
This distribution indicates that a small subset of neurons, termed hot neurons, are consistently activated
across inputs, while the majority, cold neurons, vary based on specific inputs.
PowerInfer exploits such an insight to design a GPU-CPU hybrid inference engine:
hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons are computed
on the CPU, thus significantly reducing GPU memory demands and CPU-GPU data transfers.
PowerInfer further integrates adaptive predictors and neuron-aware sparse operators,
optimizing the efficiency of neuron activation and computational sparsity.
Evaluation shows that PowerInfer attains an average token generation rate of 13.20 tokens/s, with a peak of 29.08 tokens/s, across various LLMs (including OPT-175B) on a single NVIDIA RTX 4090 GPU,
only 18\% lower than that achieved by a top-tier server-grade A100 GPU.
This significantly outperforms llama.cpp by up to 11.69x while retaining model accuracy.
## Features
PowerInfer is a high-speed and easy-to-use inference engine for deploying LLMs locally.
PowerInfer is fast with:
- **Locality-centric design**: Utilizes sparse activation and 'hot'/'cold' neuron concept for efficient LLM inference, ensuring high speed with lower resource demands.
- **Hybrid CPU/GPU Utilization**: Seamlessly integrates memory/computation capabilities of CPU and GPU for a balanced workload and faster processing.
PowerInfer is flexible and easy to use with:
- **Easy Integration**: Compatible with popular [ReLU-sparse models](https://huggingface.co/SparseLLM).
- **Local Deployment Ease**: Designed and deeply optimized for local deployment on consumer-grade hardware, enabling low-latency LLM inference and serving on a single GPU.
- **Backward Compatibility**: While distinct from llama.cpp, you can make use of most of `examples/` the same way as llama.cpp such as server and batched generation. PowerInfer also supports inference with llama.cpp's model weights for compatibility purposes, but there will be no performance gain.
You can use these models with PowerInfer today:
- Falcon-40B
- Llama2 family
- ProSparse Llama2 family
- Bamboo-7B
We have tested PowerInfer on the following platforms:
- x86-64 CPUs with AVX2 instructions, with or without NVIDIA GPUs, under **Linux**.
- x86-64 CPUs with AVX2 instructions, with or without NVIDIA GPUs, under **Windows**.
- Apple M Chips (CPU only) on **macOS**. (As we do not optimize for Mac, the performance improvement is not significant now.)
And new features coming soon:
- Metal backend for sparse inference on macOS
Please kindly refer to our [Project Kanban](https://github.com/orgs/SJTU-IPADS/projects/2/views/2) for our current focus of development.
## Getting Started
- [Installation](#setup-and-installation)
- [Model Weights](#model-weights)
- [Inference](#inference)
## Setup and Installation
### Pre-requisites
PowerInfer requires the following dependencies:
- CMake (3.17+)
- Python (3.8+) and pip (19.3+), for converting model weights and automatic FFN offloading
### Get the Code
```bash
git clone https://github.com/SJTU-IPADS/PowerInfer
cd PowerInfer
pip install -r requirements.txt # install Python helpers' dependencies
```
### Build
In order to build PowerInfer you have two different options. These commands are supposed to be run from the root directory of the project.
Using `CMake`(3.17+):
* If you have an NVIDIA GPU:
```bash
cmake -S . -B build -DLLAMA_CUBLAS=ON
cmake --build build --config Release
```
* If you have an AMD GPU:
```bash
# Replace '1100' to your card architecture name, you can get it by rocminfo
CC=/opt/rocm/llvm/bin/clang CXX=/opt/rocm/llvm/bin/clang++ cmake -S . -B build -DLLAMA_HIPBLAS=ON -DAMDGPU_TARGETS=gfx1100
cmake --build build --config Release
```
* If you have just CPU:
```bash
cmake -S . -B build
cmake --build build --config Release
```
## Model Weights
PowerInfer models are stored in a special format called *PowerInfer GGUF* based on GGUF format, consisting of both LLM weights and predictor weights.
### Download PowerInfer GGUF via Hugging Face
You can obtain PowerInfer GGUF weights at `*.powerinfer.gguf` as well as profiled model activation statistics for 'hot'-neuron offloading from each Hugging Face repo below.
| Base Model | PowerInfer GGUF |
| --------------------- | ------------------------------------------------------------------------------------------------------------- |
| LLaMA(ReLU)-2-7B | [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF) |
| LLaMA(ReLU)-2-13B | [PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) |
| Falcon(ReLU)-40B | [PowerInfer/ReluFalcon-40B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluFalcon-40B-PowerInfer-GGUF) |
| LLaMA(ReLU)-2-70B | [PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF) |
| ProSparse-LLaMA-2-7B | [PowerInfer/ProSparse-LLaMA-2-7B-GGUF](https://huggingface.co/PowerInfer/prosparse-llama-2-7b-gguf) |
| ProSparse-LLaMA-2-13B | [PowerInfer/ProSparse-LLaMA-2-13B-GGUF](https://huggingface.co/PowerInfer/prosparse-llama-2-13b-gguf) |
| Bamboo-base-7B 🌟 | [PowerInfer/Bamboo-base-v0.1-gguf](https://huggingface.co/PowerInfer/Bamboo-base-v0.1-gguf) |
| Bamboo-DPO-7B 🌟 | [PowerInfer/Bamboo-DPO-v0.1-gguf](https://huggingface.co/PowerInfer/Bamboo-DPO-v0.1-gguf) |
We recommend using [`huggingface-cli`](https://huggingface.co/docs/huggingface_hub/guides/cli) to download the whole model repo. For example, the following command will download [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF) into the `./ReluLLaMA-7B` directory.
```shell
huggingface-cli download --resume-download --local-dir ReluLLaMA-7B --local-dir-use-symlinks False PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF
```
As such, PowerInfer can automatically make use of the following directory structure for feature-complete model offloading:
```
.
├── *.powerinfer.gguf (Unquantized PowerInfer model)
├── *.q4.powerinfer.gguf (INT4 quantized PowerInfer model, if available)
├── activation (Profiled activation statistics for fine-grained FFN offloading)
│ ├── activation_x.pt (Profiled activation statistics for layer x)
│ └── ...
├── *.[q4].powerinfer.gguf.generated.gpuidx (Generated GPU index at runtime for corresponding model)
```
### Convert from Original Model Weights + Predictor Weights
Hugging Face limits single model weight to 50GiB. For unquantized models >= 40B, you can convert PowerInfer GGUF from the original model weights and predictor weights obtained from Hugging Face.
| Base Model | Original Model | Predictor |
| --------------------- | ----------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------- |
| LLaMA(ReLU)-2-7B | [SparseLLM/ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) | [PowerInfer/ReluLLaMA-7B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-7B-Predictor) |
| LLaMA(ReLU)-2-13B | [SparseLLM/ReluLLaMA-13B](https://huggingface.co/SparseLLM/ReluLLaMA-13B) | [PowerInfer/ReluLLaMA-13B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-13B-Predictor) |
| Falcon(ReLU)-40B | [SparseLLM/ReluFalcon-40B](https://huggingface.co/SparseLLM/ReluFalcon-40B) | [PowerInfer/ReluFalcon-40B-Predictor](https://huggingface.co/PowerInfer/ReluFalcon-40B-Predictor) |
| LLaMA(ReLU)-2-70B | [SparseLLM/ReluLLaMA-70B](https://huggingface.co/SparseLLM/ReluLLaMA-70B) | [PowerInfer/ReluLLaMA-70B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-70B-Predictor) |
| ProSparse-LLaMA-2-7B | [SparseLLM/ProSparse-LLaMA-2-7B](https://huggingface.co/SparseLLM/prosparse-llama-2-7b) | [PowerInfer/ProSparse-LLaMA-2-7B-Predictor](https://huggingface.co/PowerInfer/prosparse-llama-2-7b-predictor) |
| ProSparse-LLaMA-2-13B | [SparseLLM/ProSparse-LLaMA-2-13B](https://huggingface.co/SparseLLM/prosparse-llama-2-13b) | [PowerInfer/ProSparse-LLaMA-2-13B-Predictor](https://huggingface.co/PowerInfer/prosparse-llama-2-13b-predictor) |
| Bamboo-base-7B 🌟 | [PowerInfer/Bamboo-base-v0.1](https://huggingface.co/PowerInfer/Bamboo-base-v0_1) | [PowerInfer/Bamboo-base-v0.1-predictor](https://huggingface.co/PowerInfer/Bamboo-base-v0.1-predictor) |
| Bamboo-DPO-7B 🌟 | [PowerInfer/Bamboo-DPO-v0.1](https://huggingface.co/PowerInfer/Bamboo-DPO-v0_1) | [PowerInfer/Bamboo-DPO-v0.1-predictor](https://huggingface.co/PowerInfer/Bamboo-DPO-v0.1-predictor) |
You can use the following command to convert the original model weights and predictor weights to PowerInfer GGUF:
```bash
# make sure that you have done `pip install -r requirements.txt`
python convert.py --outfile /PATH/TO/POWERINFER/GGUF/REPO/MODELNAME.powerinfer.gguf /PATH/TO/ORIGINAL/MODEL /PATH/TO/PREDICTOR
# python convert.py --outfile ./ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.powerinfer.gguf ./SparseLLM/ReluLLaMA-70B ./PowerInfer/ReluLLaMA-70B-Predictor
```
For the same reason, we suggest keeping the same directory structure as PowerInfer GGUF repos after conversion.
<details>
<summary>Convert Original models into dense GGUF models(compatible with llama.cpp)</summary>
```bash
python convert-dense.py --outfile /PATH/TO/DENSE/GGUF/REPO/MODELNAME.gguf /PATH/TO/ORIGINAL/MODEL
# python convert-dense.py --outfile ./Bamboo-DPO-v0.1-gguf/bamboo-7b-dpo-v0.1.gguf --outtype f16 ./Bamboo-DPO-v0.1
```
Please note that the generated dense GGUF models might not work properly with llama.cpp, as we have altered activation functions (for ReluLLaMA and Prosparse models), or the model architecture (for Bamboo models). The dense GGUF models generated by convert-dense.py can be used for PowerInfer in dense inference mode, but might not work properly with llama.cpp.
</details>
## Inference
For CPU-only and CPU-GPU hybrid inference with all available VRAM, you can use the following instructions to run PowerInfer:
```bash
./build/bin/main -m /PATH/TO/MODEL -n $output_token_count -t $thread_num -p $prompt
# e.g.: ./build/bin/main -m ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Once upon a time"
# For Windows: .\build\bin\Release\main.exe -m .\ReluFalcon-40B-PowerInfer-GGUF\falcon-40b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Once upon a time"
```
If you want to limit the VRAM usage of GPU:
```bash
./build/bin/main -m /PATH/TO/MODEL -n $output_token_count -t $thread_num -p $prompt --vram-budget $vram_gb
# e.g.: ./build/bin/main -m ./ReluLLaMA-7B-PowerInfer-GGUF/llama-7b-relu.powerinfer.gguf -n 128 -t 8 -p "Once upon a time" --vram-budget 8
# For Windows: .\build\bin\Release\main.exe -m .\ReluLLaMA-7B-PowerInfer-GGUF\llama-7b-relu.powerinfer.gguf -n 128 -t 8 -p "Once upon a time" --vram-budget 8
```
Under CPU-GPU hybrid inference, PowerInfer will automatically offload all dense activation blocks to GPU, then split FFN and offload to GPU if possible.
<details>
<summary>Dense inference mode (limited support)</summary>
If you want to run PowerInfer to infer with the dense variants of the PowerInfer model family, you can use similarly as llama.cpp does:
```bash
./build/bin/main -m /PATH/TO/DENSE/MODEL -n $output_token_count -t $thread_num -p $prompt -ngl $num_gpu_layers
# e.g.: ./build/bin/main -m ./Bamboo-base-v0.1-gguf/bamboo-7b-v0.1.gguf -n 128 -t 8 -p "Once upon a time" -ngl 12
```
So is the case for other `examples/` like `server` and `batched_generation`. Please note that the dense inference mode is not a "compatible mode" for all models. We have altered activation functions (for ReluLLaMA and Prosparse models) in this mode to match with our model family.
</details>
## Serving, Perplexity Evaluation, and more applications
PowerInfer supports serving and batched generation with the same instructions as llama.cpp. Generally, you can use the same command as llama.cpp, except for `-ngl` argument which has been replaced by `--vram-budget` for PowerInfer. Please refer to the detailed instructions in each `examples/` directory. For example:
- [Serving](./examples/server/README.md)
- [Perplexity Evaluation](./examples/perplexity/README.md)
- [Batched Generation](./examples/batched/README.md)
## Quantization
PowerInfer has optimized quantization support for INT4(`Q4_0`) models. You can use the following instructions to quantize PowerInfer GGUF model:
```bash
./build/bin/quantize /PATH/TO/MODEL /PATH/TO/OUTPUT/QUANTIZED/MODEL Q4_0
# e.g.: ./build/bin/quantize ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.powerinfer.gguf ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.q4.powerinfer.gguf Q4_0
# For Windows: .\build\bin\Release\quantize.exe .\ReluFalcon-40B-PowerInfer-GGUF\falcon-40b-relu.powerinfer.gguf .\ReluFalcon-40B-PowerInfer-GGUF\falcon-40b-relu.q4.powerinfer.gguf Q4_0
```
Then you can use the quantized model for inference with PowerInfer with the same instructions as above.
## More Documentation
- [Performance troubleshooting](./docs/token_generation_performance_tips.md)
## Evaluation
We evaluated PowerInfer vs. llama.cpp on a single RTX 4090(24G) with a series of FP16 ReLU models under inputs of length 64, and the results are shown below. PowerInfer achieves up to 11x speedup on Falcon 40B and up to 3x speedup on Llama 2 70B.
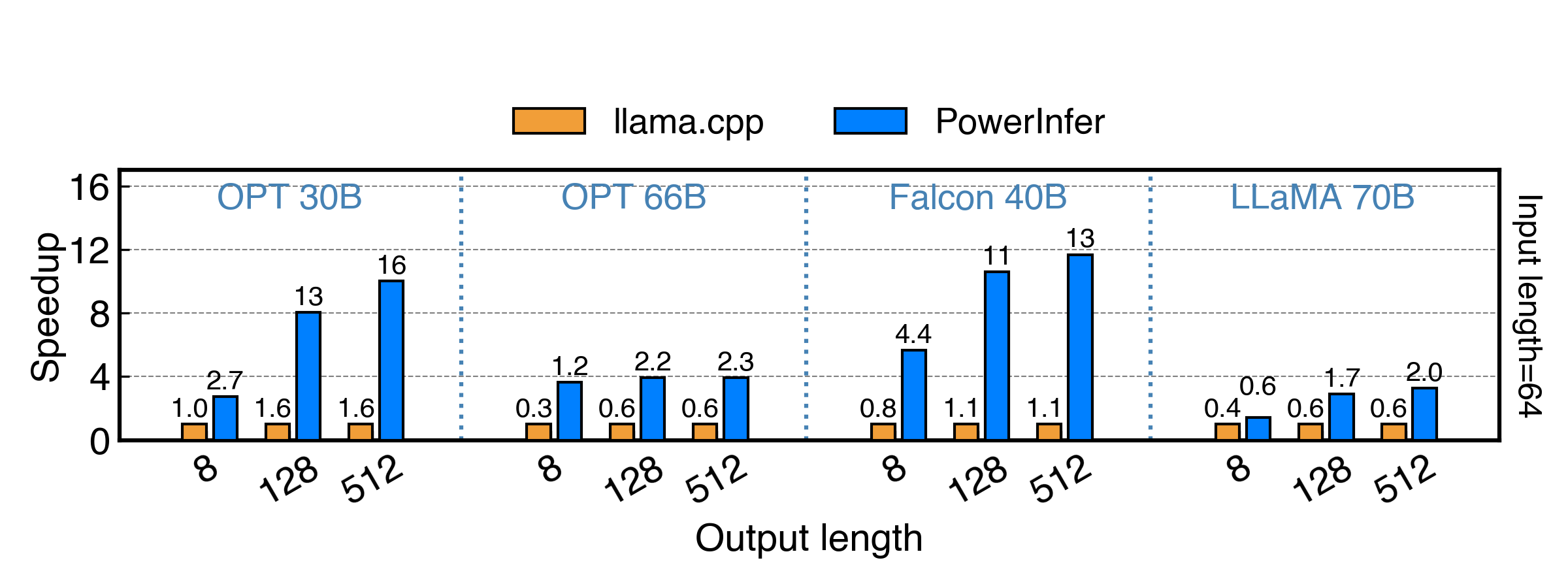
<sub>The X axis indicates the output length, and the Y axis represents the speedup compared with llama.cpp. The number above each bar indicates the end-to-end generation speed (total prompting + generation time / total tokens generated, in tokens/s).</sub>
We also evaluated PowerInfer on a single RTX 2080Ti(11G) with INT4 ReLU models under inputs of length 8, and the results are illustrated in the same way as above. PowerInfer achieves up to 8x speedup on Falcon 40B and up to 3x speedup on Llama 2 70B.
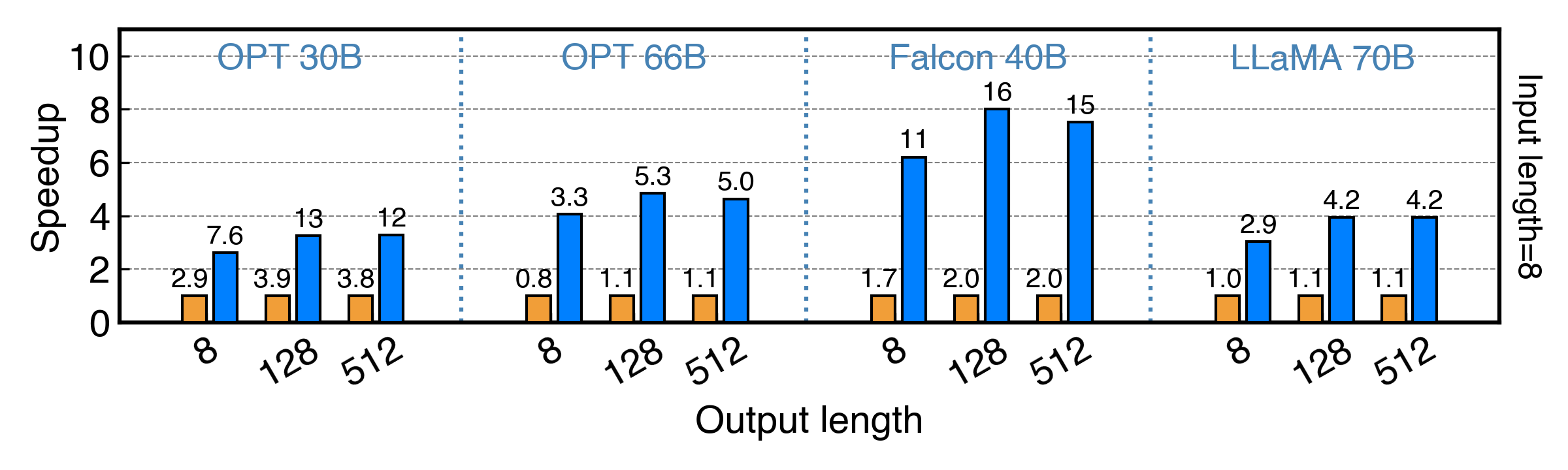
Please refer to our [paper](https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf) for more evaluation details.
## FAQs
1. What if I encountered `CUDA_ERROR_OUT_OF_MEMORY`?
- You can try to run with `--reset-gpu-index` argument to rebuild the GPU index for this model to avoid any stale cache.
- Due to our current implementation, model offloading might not be as accurate as expected. You can try with `--vram-budget` with a slightly lower value or `--disable-gpu-index` to disable FFN offloading.
2. Does PowerInfer support mistral, original llama, Qwen, ...?
- Now we only support models with ReLU/ReGLU/Squared ReLU activation function. So we do not support these models now. It's worth mentioning that a [paper](https://arxiv.org/pdf/2310.04564.pdf) has demonstrated that using the ReLU/ReGLU activation function has a negligible impact on convergence and performance.
3. Why is there a noticeable downgrade in the performance metrics of our current ReLU model, particularly the 70B model?
- In contrast to the typical requirement of around 2T tokens for LLM training, our model's fine-tuning was conducted with only 5B tokens. This insufficient retraining has resulted in the model's inability to regain its original performance. We are actively working on updating to a more capable model, so please stay tuned.
4. What if...
- Issues are welcomed! Please feel free to open an issue and attach your running environment and running parameters. We will try our best to help you.
## TODOs
We will release the code and data in the following order, please stay tuned!
- [x] Release core code of PowerInfer, supporting Llama-2, Falcon-40B.
- [x] Support ~~Mistral-7B~~ (Bamboo-7B)
- [x] Support Windows
- [ ] Support text-generation-webui
- [x] Release perplexity evaluation code
- [ ] Support Metal for Mac
- [ ] Release code for OPT models
- [ ] Release predictor training code
- [x] Support online split for FFN network
- [ ] Support Multi-GPU
## Paper and Citation
More technical details can be found in our [paper](https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf).
If you find PowerInfer useful or relevant to your project and research, please kindly cite our paper:
```bibtex
@misc{song2023powerinfer,
title={PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU},
author={Yixin Song and Zeyu Mi and Haotong Xie and Haibo Chen},
year={2023},
eprint={2312.12456},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
## Acknowledgement
We are thankful for the easily modifiable operator library [ggml](https://github.com/ggerganov/ggml) and execution runtime provided by [llama.cpp](https://github.com/ggerganov/llama.cpp). We also extend our gratitude to [THUNLP](https://nlp.csai.tsinghua.edu.cn/) for their support of ReLU-based sparse models. We also appreciate the research of [Deja Vu](https://proceedings.mlr.press/v202/liu23am.html), which inspires PowerInfer.
", Assign "at most 3 tags" to the expected json: {"id":"6186","tags":[]} "only from the tags list I provide: [{"id":77,"name":"3d"},{"id":89,"name":"agent"},{"id":17,"name":"ai"},{"id":54,"name":"algorithm"},{"id":24,"name":"api"},{"id":44,"name":"authentication"},{"id":3,"name":"aws"},{"id":27,"name":"backend"},{"id":60,"name":"benchmark"},{"id":72,"name":"best-practices"},{"id":39,"name":"bitcoin"},{"id":37,"name":"blockchain"},{"id":1,"name":"blog"},{"id":45,"name":"bundler"},{"id":58,"name":"cache"},{"id":21,"name":"chat"},{"id":49,"name":"cicd"},{"id":4,"name":"cli"},{"id":64,"name":"cloud-native"},{"id":48,"name":"cms"},{"id":61,"name":"compiler"},{"id":68,"name":"containerization"},{"id":92,"name":"crm"},{"id":34,"name":"data"},{"id":47,"name":"database"},{"id":8,"name":"declarative-gui "},{"id":9,"name":"deploy-tool"},{"id":53,"name":"desktop-app"},{"id":6,"name":"dev-exp-lib"},{"id":59,"name":"dev-tool"},{"id":13,"name":"ecommerce"},{"id":26,"name":"editor"},{"id":66,"name":"emulator"},{"id":62,"name":"filesystem"},{"id":80,"name":"finance"},{"id":15,"name":"firmware"},{"id":73,"name":"for-fun"},{"id":2,"name":"framework"},{"id":11,"name":"frontend"},{"id":22,"name":"game"},{"id":81,"name":"game-engine "},{"id":23,"name":"graphql"},{"id":84,"name":"gui"},{"id":91,"name":"http"},{"id":5,"name":"http-client"},{"id":51,"name":"iac"},{"id":30,"name":"ide"},{"id":78,"name":"iot"},{"id":40,"name":"json"},{"id":83,"name":"julian"},{"id":38,"name":"k8s"},{"id":31,"name":"language"},{"id":10,"name":"learning-resource"},{"id":33,"name":"lib"},{"id":41,"name":"linter"},{"id":28,"name":"lms"},{"id":16,"name":"logging"},{"id":76,"name":"low-code"},{"id":90,"name":"message-queue"},{"id":42,"name":"mobile-app"},{"id":18,"name":"monitoring"},{"id":36,"name":"networking"},{"id":7,"name":"node-version"},{"id":55,"name":"nosql"},{"id":57,"name":"observability"},{"id":46,"name":"orm"},{"id":52,"name":"os"},{"id":14,"name":"parser"},{"id":74,"name":"react"},{"id":82,"name":"real-time"},{"id":56,"name":"robot"},{"id":65,"name":"runtime"},{"id":32,"name":"sdk"},{"id":71,"name":"search"},{"id":63,"name":"secrets"},{"id":25,"name":"security"},{"id":85,"name":"server"},{"id":86,"name":"serverless"},{"id":70,"name":"storage"},{"id":75,"name":"system-design"},{"id":79,"name":"terminal"},{"id":29,"name":"testing"},{"id":12,"name":"ui"},{"id":50,"name":"ux"},{"id":88,"name":"video"},{"id":20,"name":"web-app"},{"id":35,"name":"web-server"},{"id":43,"name":"webassembly"},{"id":69,"name":"workflow"},{"id":87,"name":"yaml"}]" returns me the "expected json"