base on OpenCompass is an LLM evaluation platform, supporting a wide range of models (Llama3, Mistral, InternLM2,GPT-4,LLaMa2, Qwen,GLM, Claude, etc) over 100+ datasets. <div align="center">
<img src="docs/en/_static/image/logo.svg" width="500px"/>
<br />
<br />
[![][github-release-shield]][github-release-link]
[![][github-releasedate-shield]][github-releasedate-link]
[![][github-contributors-shield]][github-contributors-link]<br>
[![][github-forks-shield]][github-forks-link]
[![][github-stars-shield]][github-stars-link]
[![][github-issues-shield]][github-issues-link]
[![][github-license-shield]][github-license-link]
<!-- [](https://pypi.org/project/opencompass/) -->
[🌐Website](https://opencompass.org.cn/) |
[📖CompassHub](https://hub.opencompass.org.cn/home) |
[📊CompassRank](https://rank.opencompass.org.cn/home) |
[📘Documentation](https://opencompass.readthedocs.io/en/latest/) |
[🛠️Installation](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) |
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
English | [简体中文](README_zh-CN.md)
[![][github-trending-shield]][github-trending-url]
</div>
<p align="center">
👋 join us on <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> and <a href="https://r.vansin.top/?r=opencompass" target="_blank">WeChat</a>
</p>
> \[!IMPORTANT\]
>
> **Star Us**, You will receive all release notifications from GitHub without any delay ~ ⭐️
<details>
<summary><kbd>Star History</kbd></summary>
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&theme=dark&type=Date">
<img width="100%" src="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&type=Date">
</picture>
</details>
## 🧭 Welcome
to **OpenCompass**!
Just like a compass guides us on our journey, OpenCompass will guide you through the complex landscape of evaluating large language models. With its powerful algorithms and intuitive interface, OpenCompass makes it easy to assess the quality and effectiveness of your NLP models.
🚩🚩🚩 Explore opportunities at OpenCompass! We're currently **hiring full-time researchers/engineers and interns**. If you're passionate about LLM and OpenCompass, don't hesitate to reach out to us via [email](mailto:
[email protected]). We'd love to hear from you!
🔥🔥🔥 We are delighted to announce that **the OpenCompass has been recommended by the Meta AI**, click [Get Started](https://ai.meta.com/llama/get-started/#validation) of Llama for more information.
> **Attention**<br />
> Breaking Change Notice: In version 0.4.0, we are consolidating all AMOTIC configuration files (previously located in ./configs/datasets, ./configs/models, and ./configs/summarizers) into the opencompass package. Users are advised to update their configuration references to reflect this structural change.
## 🚀 What's New <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
- **\[2025.04.01\]** OpenCompass now supports `CascadeEvaluator`, a flexible evaluation mechanism that allows multiple evaluators to work in sequence. This enables creating customized evaluation pipelines for complex assessment scenarios. Check out the [documentation](docs/en/advanced_guides/llm_judge.md) for more details! 🔥🔥🔥
- **\[2025.03.11\]** We have supported evaluation for `SuperGPQA` which is a great benchmark for measuring LLM knowledge ability 🔥🔥🔥
- **\[2025.02.28\]** We have added a tutorial for `DeepSeek-R1` series model, please check [Evaluating Reasoning Model](docs/en/user_guides/deepseek_r1.md) for more details! 🔥🔥🔥
- **\[2025.02.15\]** We have added two powerful evaluation tools: `GenericLLMEvaluator` for LLM-as-judge evaluations and `MATHVerifyEvaluator` for mathematical reasoning assessments. Check out the documentation for [LLM Judge](docs/en/advanced_guides/llm_judge.md) and [Math Evaluation](docs/en/advanced_guides/general_math.md) for more details! 🔥🔥🔥
- **\[2025.01.16\]** We now support the [InternLM3-8B-Instruct](https://huggingface.co/internlm/internlm3-8b-instruct) model which has enhanced performance on reasoning and knowledge-intensive tasks.
- **\[2024.12.17\]** We have provided the evaluation script for the December [CompassAcademic](examples/eval_academic_leaderboard_202412.py), which allows users to easily reproduce the official evaluation results by configuring it.
- **\[2024.11.14\]** OpenCompass now offers support for a sophisticated benchmark designed to evaluate complex reasoning skills — [MuSR](https://arxiv.org/pdf/2310.16049). Check out the [demo](examples/eval_musr.py) and give it a spin! 🔥🔥🔥
- **\[2024.11.14\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [BABILong](https://arxiv.org/pdf/2406.10149). Have a look at the [demo](examples/eval_babilong.py) and give it a try! 🔥🔥🔥
- **\[2024.10.14\]** We now support the OpenAI multilingual QA dataset [MMMLU](https://huggingface.co/datasets/openai/MMMLU). Feel free to give it a try! 🔥🔥🔥
- **\[2024.09.19\]** We now support [Qwen2.5](https://huggingface.co/Qwen)(0.5B to 72B) with multiple backend(huggingface/vllm/lmdeploy). Feel free to give them a try! 🔥🔥🔥
- **\[2024.09.17\]** We now support OpenAI o1(`o1-mini-2024-09-12` and `o1-preview-2024-09-12`). Feel free to give them a try! 🔥🔥🔥
- **\[2024.09.05\]** We now support answer extraction through model post-processing to provide a more accurate representation of the model's capabilities. As part of this update, we have integrated [XFinder](https://github.com/IAAR-Shanghai/xFinder) as our first post-processing model. For more detailed information, please refer to the [documentation](opencompass/utils/postprocessors/xfinder/README.md), and give it a try! 🔥🔥🔥
- **\[2024.08.20\]** OpenCompass now supports the [SciCode](https://github.com/scicode-bench/SciCode): A Research Coding Benchmark Curated by Scientists. 🔥🔥🔥
- **\[2024.08.16\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [RULER](https://arxiv.org/pdf/2404.06654). RULER provides an evaluation of long-context including retrieval, multi-hop tracing, aggregation, and question answering through flexible configurations. Check out the [RULER](configs/datasets/ruler/README.md) evaluation config now! 🔥🔥🔥
- **\[2024.08.09\]** We have released the example data and configuration for the CompassBench-202408, welcome to [CompassBench](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_intro.html) for more details. 🔥🔥🔥
- **\[2024.08.01\]** We supported the [Gemma2](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315) models. Welcome to try! 🔥🔥🔥
- **\[2024.07.23\]** We supported the [ModelScope](www.modelscope.cn) datasets, you can load them on demand without downloading all the data to your local disk. Welcome to try! 🔥🔥🔥
- **\[2024.07.17\]** We are excited to announce the release of NeedleBench's [technical report](http://arxiv.org/abs/2407.11963). We invite you to visit our [support documentation](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html) for detailed evaluation guidelines. 🔥🔥🔥
- **\[2024.07.04\]** OpenCompass now supports InternLM2.5, which has **outstanding reasoning capability**, **1M Context window and** and **stronger tool use**, you can try the models in [OpenCompass Config](https://github.com/open-compass/opencompass/tree/main/configs/models/hf_internlm) and [InternLM](https://github.com/InternLM/InternLM) .🔥🔥🔥.
- **\[2024.06.20\]** OpenCompass now supports one-click switching between inference acceleration backends, enhancing the efficiency of the evaluation process. In addition to the default HuggingFace inference backend, it now also supports popular backends [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm). This feature is available via a simple command-line switch and through deployment APIs. For detailed usage, see the [documentation](docs/en/advanced_guides/accelerator_intro.md).🔥🔥🔥.
> [More](docs/en/notes/news.md)
## 📊 Leaderboard
We provide [OpenCompass Leaderboard](https://rank.opencompass.org.cn/home) for the community to rank all public models and API models. If you would like to join the evaluation, please provide the model repository URL or a standard API interface to the email address `
[email protected]`.
You can also refer to [CompassAcademic](configs/eval_academic_leaderboard_202412.py) to quickly reproduce the leaderboard results. The currently selected datasets include Knowledge Reasoning (MMLU-Pro/GPQA Diamond), Logical Reasoning (BBH), Mathematical Reasoning (MATH-500, AIME), Code Generation (LiveCodeBench, HumanEval), and Instruction Following (IFEval)."
<p align="right"><a href="#top">🔝Back to top</a></p>
## 🛠️ Installation
Below are the steps for quick installation and datasets preparation.
### 💻 Environment Setup
We highly recommend using conda to manage your python environment.
- #### Create your virtual environment
```bash
conda create --name opencompass python=3.10 -y
conda activate opencompass
```
- #### Install OpenCompass via pip
```bash
pip install -U opencompass
## Full installation (with support for more datasets)
# pip install "opencompass[full]"
## Environment with model acceleration frameworks
## Manage different acceleration frameworks using virtual environments
## since they usually have dependency conflicts with each other.
# pip install "opencompass[lmdeploy]"
# pip install "opencompass[vllm]"
## API evaluation (i.e. Openai, Qwen)
# pip install "opencompass[api]"
```
- #### Install OpenCompass from source
If you want to use opencompass's latest features, or develop new features, you can also build it from source
```bash
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .
# pip install -e ".[full]"
# pip install -e ".[vllm]"
```
### 📂 Data Preparation
You can choose one for the following method to prepare datasets.
#### Offline Preparation
You can download and extract the datasets with the following commands:
```bash
# Download dataset to data/ folder
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
```
#### Automatic Download from OpenCompass
We have supported download datasets automatic from the OpenCompass storage server. You can run the evaluation with extra `--dry-run` to download these datasets.
Currently, the supported datasets are listed in [here](https://github.com/open-compass/opencompass/blob/main/opencompass/utils/datasets_info.py#L259). More datasets will be uploaded recently.
#### (Optional) Automatic Download with ModelScope
Also you can use the [ModelScope](www.modelscope.cn) to load the datasets on demand.
Installation:
```bash
pip install modelscope[framework]
export DATASET_SOURCE=ModelScope
```
Then submit the evaluation task without downloading all the data to your local disk. Available datasets include:
```bash
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
```
Some third-party features, like Humaneval and Llama, may require additional steps to work properly, for detailed steps please refer to the [Installation Guide](https://opencompass.readthedocs.io/en/latest/get_started/installation.html).
<p align="right"><a href="#top">🔝Back to top</a></p>
## 🏗️ ️Evaluation
After ensuring that OpenCompass is installed correctly according to the above steps and the datasets are prepared. Now you can start your first evaluation using OpenCompass!
### Your first evaluation with OpenCompass!
OpenCompass support setting your configs via CLI or a python script. For simple evaluation settings we recommend using CLI, for more complex evaluation, it is suggested using the script way. You can find more example scripts under the configs folder.
```bash
# CLI
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen
# Python scripts
opencompass examples/eval_chat_demo.py
```
You can find more script examples under [examples](./examples) folder.
### API evaluation
OpenCompass, by its design, does not really discriminate between open-source models and API models. You can evaluate both model types in the same way or even in one settings.
```bash
export OPENAI_API_KEY="YOUR_OPEN_API_KEY"
# CLI
opencompass --models gpt_4o_2024_05_13 --datasets demo_gsm8k_chat_gen
# Python scripts
opencompass examples/eval_api_demo.py
# You can use o1_mini_2024_09_12/o1_preview_2024_09_12 for o1 models, we set max_completion_tokens=8192 as default.
```
### Accelerated Evaluation
Additionally, if you want to use an inference backend other than HuggingFace for accelerated evaluation, such as LMDeploy or vLLM, you can do so with the command below. Please ensure that you have installed the necessary packages for the chosen backend and that your model supports accelerated inference with it. For more information, see the documentation on inference acceleration backends [here](docs/en/advanced_guides/accelerator_intro.md). Below is an example using LMDeploy:
```bash
# CLI
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen -a lmdeploy
# Python scripts
opencompass examples/eval_lmdeploy_demo.py
```
### Supported Models and Datasets
OpenCompass has predefined configurations for many models and datasets. You can list all available model and dataset configurations using the [tools](./docs/en/tools.md#list-configs).
```bash
# List all configurations
python tools/list_configs.py
# List all configurations related to llama and mmlu
python tools/list_configs.py llama mmlu
```
#### Supported Models
If the model is not on the list but supported by Huggingface AutoModel class or encapsulation of inference engine based on OpenAI interface (see [docs](https://opencompass.readthedocs.io/en/latest/advanced_guides/new_model.html) for details), you can also evaluate it with OpenCompass. You are welcome to contribute to the maintenance of the OpenCompass supported model and dataset lists.
```bash
opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat
```
#### Supported Datasets
Currently, OpenCompass have provided standard recommended configurations for datasets. Generally, config files ending with `_gen.py` or `_llm_judge_gen.py` will point to the recommended config we provide for this dataset. You can refer to [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for more details.
```bash
# Recommended Evaluation Config based on Rules
opencompass --datasets aime2024_gen --models hf_internlm2_5_1_8b_chat
# Recommended Evaluation Config based on LLM Judge
opencompass --datasets aime2024_llmjudge_gen --models hf_internlm2_5_1_8b_chat
```
If you want to use multiple GPUs to evaluate the model in data parallel, you can use `--max-num-worker`.
```bash
CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2
```
> \[!TIP\]
>
> `--hf-num-gpus` is used for model parallel(huggingface format), `--max-num-worker` is used for data parallel.
> \[!TIP\]
>
> configuration with `_ppl` is designed for base model typically.
> configuration with `_gen` can be used for both base model and chat model.
Through the command line or configuration files, OpenCompass also supports evaluating APIs or custom models, as well as more diversified evaluation strategies. Please read the [Quick Start](https://opencompass.readthedocs.io/en/latest/get_started/quick_start.html) to learn how to run an evaluation task.
<p align="right"><a href="#top">🔝Back to top</a></p>
## 📣 OpenCompass 2.0
We are thrilled to introduce OpenCompass 2.0, an advanced suite featuring three key components: [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home).
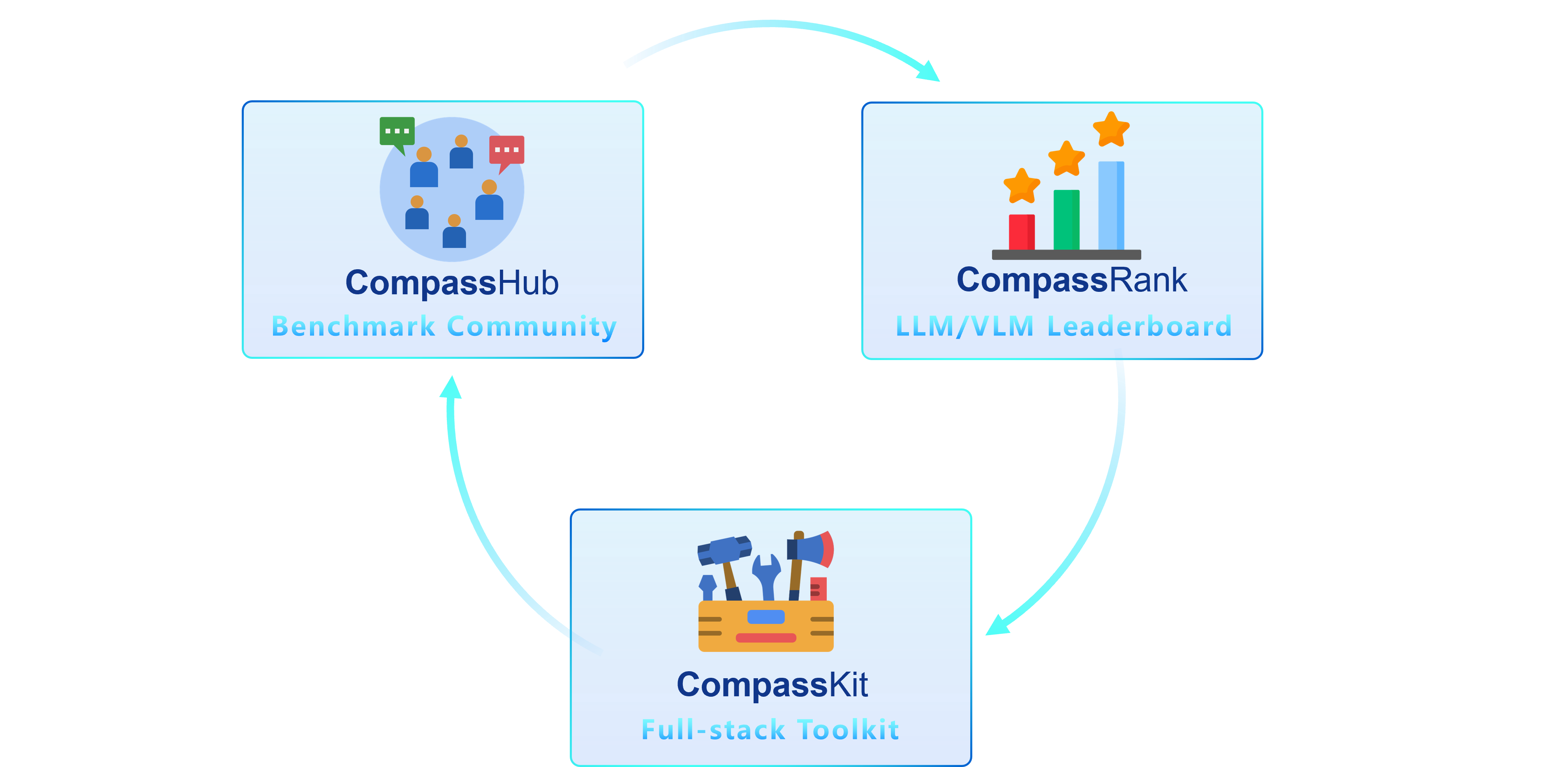
**CompassRank** has been significantly enhanced into the leaderboards that now incorporates both open-source benchmarks and proprietary benchmarks. This upgrade allows for a more comprehensive evaluation of models across the industry.
**CompassHub** presents a pioneering benchmark browser interface, designed to simplify and expedite the exploration and utilization of an extensive array of benchmarks for researchers and practitioners alike. To enhance the visibility of your own benchmark within the community, we warmly invite you to contribute it to CompassHub. You may initiate the submission process by clicking [here](https://hub.opencompass.org.cn/dataset-submit).
**CompassKit** is a powerful collection of evaluation toolkits specifically tailored for Large Language Models and Large Vision-language Models. It provides an extensive set of tools to assess and measure the performance of these complex models effectively. Welcome to try our toolkits for in your research and products.
## ✨ Introduction
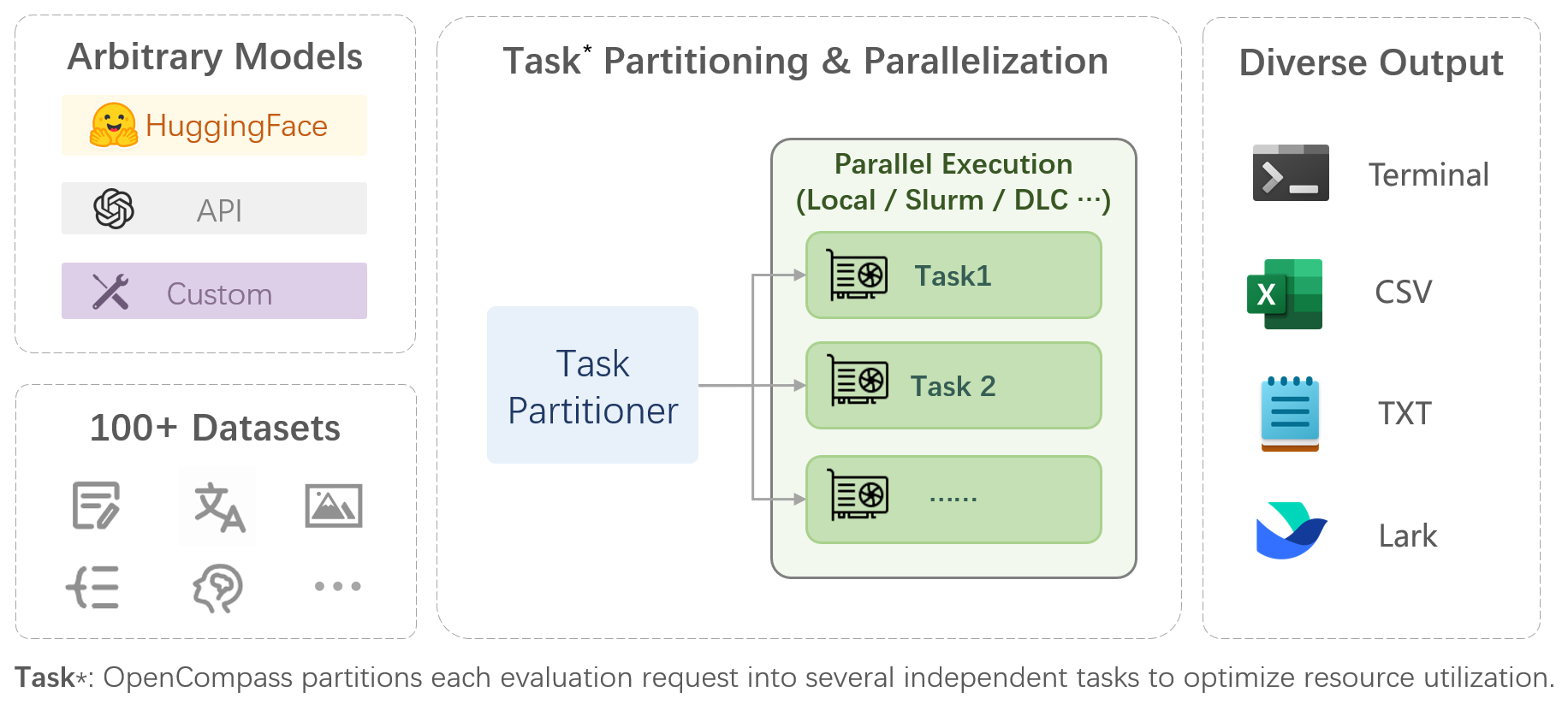
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include:
- **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions.
- **Efficient distributed evaluation**: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours.
- **Diversified evaluation paradigms**: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models.
- **Modular design with high extensibility**: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded!
- **Experiment management and reporting mechanism**: Use config files to fully record each experiment, and support real-time reporting of results.
## 📖 Dataset Support
We have supported a statistical list of all datasets that can be used on this platform in the documentation on the OpenCompass website.
You can quickly find the dataset you need from the list through sorting, filtering, and searching functions.
In addition, we provide a recommended configuration for each dataset, and some datasets also support LLM Judge-based configurations.
Please refer to the dataset statistics chapter of [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for details.
<p align="right"><a href="#top">🔝Back to top</a></p>
## 📖 Model Support
<table align="center">
<tbody>
<tr align="center" valign="bottom">
<td>
<b>Open-source Models</b>
</td>
<td>
<b>API Models</b>
</td>
<!-- <td>
<b>Custom Models</b>
</td> -->
</tr>
<tr valign="top">
<td>
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
- [Baichuan](https://github.com/baichuan-inc)
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
- [Gemma](https://huggingface.co/google/gemma-7b)
- [InternLM](https://github.com/InternLM/InternLM)
- [LLaMA](https://github.com/facebookresearch/llama)
- [LLaMA3](https://github.com/meta-llama/llama3)
- [Qwen](https://github.com/QwenLM/Qwen)
- [TigerBot](https://github.com/TigerResearch/TigerBot)
- [Vicuna](https://github.com/lm-sys/FastChat)
- [WizardLM](https://github.com/nlpxucan/WizardLM)
- [Yi](https://github.com/01-ai/Yi)
- ……
</td>
<td>
- OpenAI
- Gemini
- Claude
- ZhipuAI(ChatGLM)
- Baichuan
- ByteDance(YunQue)
- Huawei(PanGu)
- 360
- Baidu(ERNIEBot)
- MiniMax(ABAB-Chat)
- SenseTime(nova)
- Xunfei(Spark)
- ……
</td>
</tr>
</tbody>
</table>
<p align="right"><a href="#top">🔝Back to top</a></p>
## 🔜 Roadmap
- [x] Subjective Evaluation
- [x] Release CompassAreana.
- [x] Subjective evaluation.
- [x] Long-context
- [x] Long-context evaluation with extensive datasets.
- [ ] Long-context leaderboard.
- [x] Coding
- [ ] Coding evaluation leaderboard.
- [x] Non-python language evaluation service.
- [x] Agent
- [ ] Support various agent frameworks.
- [x] Evaluation of tool use of the LLMs.
- [x] Robustness
- [x] Support various attack methods.
## 👷♂️ Contributing
We appreciate all contributions to improving OpenCompass. Please refer to the [contributing guideline](https://opencompass.readthedocs.io/en/latest/notes/contribution_guide.html) for the best practice.
<!-- Copy-paste in your Readme.md file -->
<!-- Made with [OSS Insight](https://ossinsight.io/) -->
<a href="https://github.com/open-compass/opencompass/graphs/contributors" target="_blank">
<table>
<tr>
<th colspan="2">
<br><img src="https://contrib.rocks/image?repo=open-compass/opencompass"><br><br>
</th>
</tr>
</table>
</a>
## 🤝 Acknowledgements
Some code in this project is cited and modified from [OpenICL](https://github.com/Shark-NLP/OpenICL).
Some datasets and prompt implementations are modified from [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub) and [instruct-eval](https://github.com/declare-lab/instruct-eval).
## 🖊️ Citation
```bibtex
@misc{2023opencompass,
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
author={OpenCompass Contributors},
howpublished = {\url{https://github.com/open-compass/opencompass}},
year={2023}
}
```
<p align="right"><a href="#top">🔝Back to top</a></p>
[github-contributors-link]: https://github.com/open-compass/opencompass/graphs/contributors
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/opencompass?color=c4f042&labelColor=black&style=flat-square
[github-forks-link]: https://github.com/open-compass/opencompass/network/members
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/opencompass?color=8ae8ff&labelColor=black&style=flat-square
[github-issues-link]: https://github.com/open-compass/opencompass/issues
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/opencompass?color=ff80eb&labelColor=black&style=flat-square
[github-license-link]: https://github.com/open-compass/opencompass/blob/main/LICENSE
[github-license-shield]: https://img.shields.io/github/license/open-compass/opencompass?color=white&labelColor=black&style=flat-square
[github-release-link]: https://github.com/open-compass/opencompass/releases
[github-release-shield]: https://img.shields.io/github/v/release/open-compass/opencompass?color=369eff&labelColor=black&logo=github&style=flat-square
[github-releasedate-link]: https://github.com/open-compass/opencompass/releases
[github-releasedate-shield]: https://img.shields.io/github/release-date/open-compass/opencompass?labelColor=black&style=flat-square
[github-stars-link]: https://github.com/open-compass/opencompass/stargazers
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/opencompass?color=ffcb47&labelColor=black&style=flat-square
[github-trending-shield]: https://trendshift.io/api/badge/repositories/6630
[github-trending-url]: https://trendshift.io/repositories/6630
", Assign "at most 3 tags" to the expected json: {"id":"6630","tags":[]} "only from the tags list I provide: [{"id":77,"name":"3d"},{"id":89,"name":"agent"},{"id":17,"name":"ai"},{"id":54,"name":"algorithm"},{"id":24,"name":"api"},{"id":44,"name":"authentication"},{"id":3,"name":"aws"},{"id":27,"name":"backend"},{"id":60,"name":"benchmark"},{"id":72,"name":"best-practices"},{"id":39,"name":"bitcoin"},{"id":37,"name":"blockchain"},{"id":1,"name":"blog"},{"id":45,"name":"bundler"},{"id":58,"name":"cache"},{"id":21,"name":"chat"},{"id":49,"name":"cicd"},{"id":4,"name":"cli"},{"id":64,"name":"cloud-native"},{"id":48,"name":"cms"},{"id":61,"name":"compiler"},{"id":68,"name":"containerization"},{"id":92,"name":"crm"},{"id":34,"name":"data"},{"id":47,"name":"database"},{"id":8,"name":"declarative-gui "},{"id":9,"name":"deploy-tool"},{"id":53,"name":"desktop-app"},{"id":6,"name":"dev-exp-lib"},{"id":59,"name":"dev-tool"},{"id":13,"name":"ecommerce"},{"id":26,"name":"editor"},{"id":66,"name":"emulator"},{"id":62,"name":"filesystem"},{"id":80,"name":"finance"},{"id":15,"name":"firmware"},{"id":73,"name":"for-fun"},{"id":2,"name":"framework"},{"id":11,"name":"frontend"},{"id":22,"name":"game"},{"id":81,"name":"game-engine "},{"id":23,"name":"graphql"},{"id":84,"name":"gui"},{"id":91,"name":"http"},{"id":5,"name":"http-client"},{"id":51,"name":"iac"},{"id":30,"name":"ide"},{"id":78,"name":"iot"},{"id":40,"name":"json"},{"id":83,"name":"julian"},{"id":38,"name":"k8s"},{"id":31,"name":"language"},{"id":10,"name":"learning-resource"},{"id":33,"name":"lib"},{"id":41,"name":"linter"},{"id":28,"name":"lms"},{"id":16,"name":"logging"},{"id":76,"name":"low-code"},{"id":90,"name":"message-queue"},{"id":42,"name":"mobile-app"},{"id":18,"name":"monitoring"},{"id":36,"name":"networking"},{"id":7,"name":"node-version"},{"id":55,"name":"nosql"},{"id":57,"name":"observability"},{"id":46,"name":"orm"},{"id":52,"name":"os"},{"id":14,"name":"parser"},{"id":74,"name":"react"},{"id":82,"name":"real-time"},{"id":56,"name":"robot"},{"id":65,"name":"runtime"},{"id":32,"name":"sdk"},{"id":71,"name":"search"},{"id":63,"name":"secrets"},{"id":25,"name":"security"},{"id":85,"name":"server"},{"id":86,"name":"serverless"},{"id":70,"name":"storage"},{"id":75,"name":"system-design"},{"id":79,"name":"terminal"},{"id":29,"name":"testing"},{"id":12,"name":"ui"},{"id":50,"name":"ux"},{"id":88,"name":"video"},{"id":20,"name":"web-app"},{"id":35,"name":"web-server"},{"id":43,"name":"webassembly"},{"id":69,"name":"workflow"},{"id":87,"name":"yaml"}]" returns me the "expected json"